
全国中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2020-09-07 来源:黑马程序员 浏览量:
本文的目的是向NLP爱好者们详细解析一个著名的语言模型-BERT。 全文将分4个部分由浅入深的依次讲解。
1.Bert简介
BERT是2018年10月由Google AI研究院提出的一种预训练模型。
BERT的全称是Bidirectional Encoder Representation from Transformers。BERT在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩: 全部两个衡量指标上全面超越人类,并且在11种不同NLP测试中创出SOTA表现,包括将GLUE基准推高至80.4% (绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进5.6%),成为NLP发展史上的里程碑式的模型成就。
2.关于Bert的模型架构
总体架构:如下图所示, 最左边的就是BERT的架构图,可以很清楚的看到BERT采用了Transformer Encoder block进行连接, 因为是一个典型的双向编码模型。
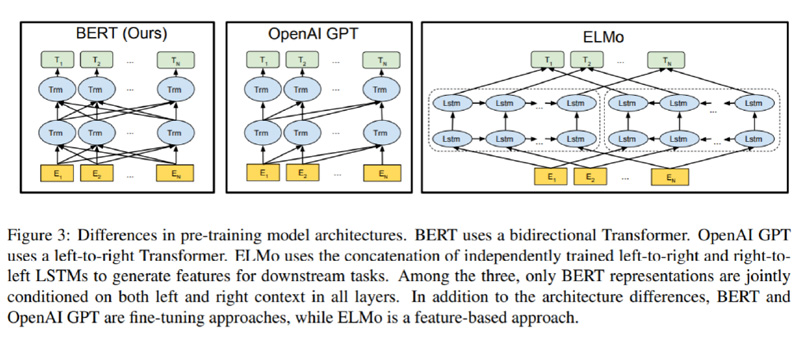
3.1 关于Bert训练过程中的关键点
1)四大关键词: Pre-trained, Deep, Bidirectional Transformer, Language Understanding
a. Pre-trained: 首先明确这是个预训练的语言模型,未来所有的开发者可以直接继承!
整个Bert模型最大的两个亮点都集中在Pre-trained的任务部分。
b. Deep
Bert_BASE:Layer = 12, Hidden = 768, Head = 12, Total Parameters = 110M
Bert_LARGE:Layer = 24, Hidden = 1024, Head = 16, Total Parameters = 340M
对比于Transformer: Layer = 6, Hidden = 2048, Head = 8,是个浅而宽,说明Bert这样深而窄的模型效果更好(和CV领域的总体结论基本一致)。
C. Bidirectional Transformer: Bert的个创新点,它是个双向的Transformer网络。
Bert直接引用了Transformer架构中的Encoder模块,并舍弃了Decoder模块, 这样便自动拥有了双向编码能力和强大的特征提取能力。
D. Language Understanding: 更加侧重语言的理解,而不仅仅是生成(Language Generation)
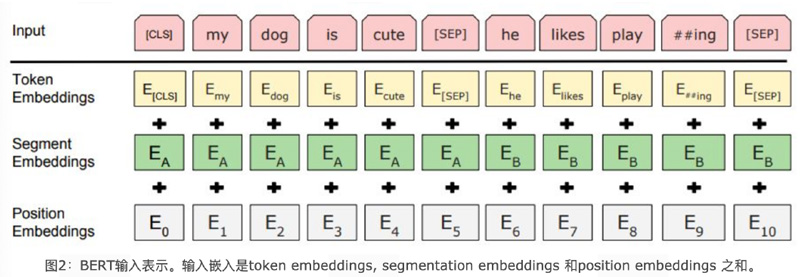
3.2 Bert的语言输入表示包含了3个组成部分: (见上面第二张图)
词嵌入张量: word embeddings
语句分块张量: segmentation embeddings
位置编码张量: position embeddings
最终的embedding向量是将上述的3个向量直接做加和的结果。
3.3: Bert的预训练中引入两大核心任务 (这两个任务也是Bert原始论文的两个最大的创新点)
a 引入Masked LM(带mask的语言模型训练)
a.1 在原始训练文本中,随机的抽取15%的token作为即将参与mask的对象。
a.2 在这些被选中的token中,数据⽣生成器器并不不是把他们全部变成[MASK],⽽而是有下列列3个选择:
a.2.1 在80%的概率下,用[MASK]标记替换该token, 比如my dog is hairy -> my dog is [MASK]
a.2.2 在10%的概率下, ⽤⼀个随机的单词替换该token, 比如my dog is hairy -> my dog is apple
a.2.3 在10%的概率下, 保持该token不变, 比如my dog is hairy -> my dog is hairy
a.3 Transformer Encoder在训练的过程中, 并不知道它将要预测哪些单词? 哪些单词是原始的样? 哪些单词被遮掩成了[MASK]? 哪些单词被替换成了其他单词? 正是在这样一种高度不确定的情况下, 反倒逼着模型快速学习该token的分布式上下文的语义, 尽最大努力学习原始语言说话的样子!!! 同时因为原始文本中只有15%的token参与了MASK操作, 并不会破坏原语言的表达能力和语言规则!!!
b 引入Next Sentence Prediction (下⼀句话的预测任务)
b.1 目的是为了服务问答,推理,句⼦主题关系等NLP任务。
b.2 所有的参与任务训练的语句都被选中参加。
·50%的B是原始⽂本中实际跟随A的下⼀句话。(标记为IsNext,代表正样本)
·50%的B是原始⽂本中随机抽取的⼀句话。(标记为NotNext,代表负样本)
b.3 在该任务中,Bert模型可以在测试集上取得97-98%的准确率。
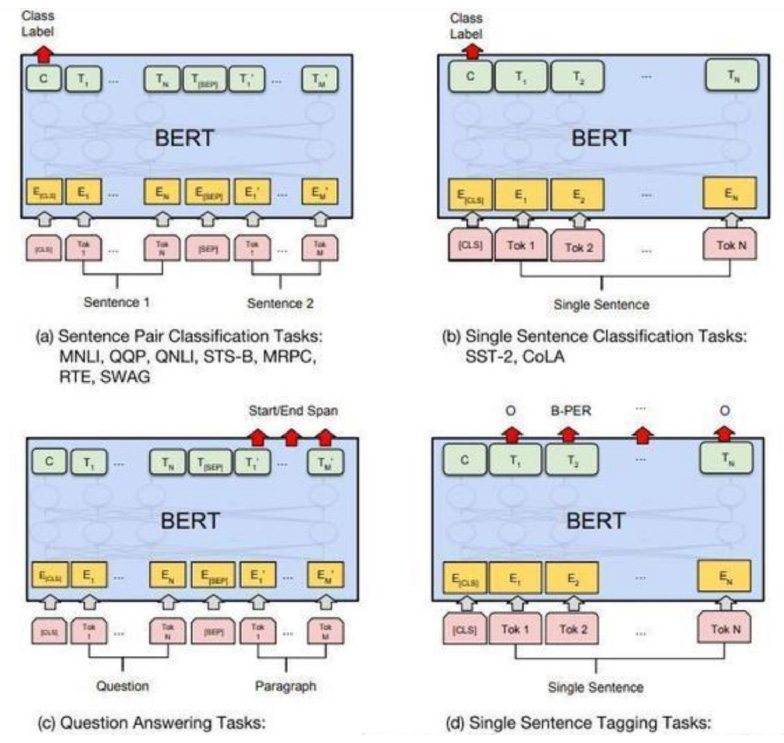
3.4 关于基于Bert的模型微调(fine-tuning)
只需要将特定任务的输入,输出插入到Bert中,利用Transformer强大的注意力机制就可以模拟很多下游任务。(句子对关系判断,单文本主题分类,问答任务(QA),单句贴标签(命名实体识别))
微调的若干经验:
batch size:16,32
epochs:3,4
learning rate:2e-5,5e-5
全连接层添加:layers:1-3,hidden_size:64,128
4、Bert模型本身的优点和缺点。
优点: Bert的基础建立在transformer之上,拥有强大的语言表征能力和特征提取能力。在11项 NLP基准测试任务中达到了state of the art。同时再次证明了双向语言模型的能力更加强大。
缺点:
1)可复现性差,基本没法做,只能拿来主义直接用!
2)训练过程中因为每个batch_size中的数据只有15%参与预测,模型收敛较慢,需要强大的算力支撑!
引申:
1)深度学习就是表征学习 (Deep learning is representation learning)
·整个Bert在11项语言模型大赛中,基本思路就是双向Transformer负责提取特征,然后整个网络加一个全连接线性层作为fine-tuning微调。但即便如此傻瓜式的组装,在NLP中著名的难任务-NER(命名实体识别)中,甚至直接去除掉了CRF层,照样大超越BiLSTM + CRF的组合效果, 这去哪儿说理去???
2)规模的极端重要性 (Scale matters)
不管是Masked LM,还是下一句预测Next Sentence Prediction,都不是首创的概念,之前在其他的模型中也提出过,但是因为数据规模+算力局限没能让世人看到这个模型的潜力,那些Paper也就不值钱了。但是到了谷歌手里, 不差钱的结果就是Paper值钱了!!
3)关于进一步的研究展示了Bert在不同的层学习到了什么。
·低的网络层捕捉到了短语结构方面的信息。
·单词和字的特征表现在3-4层,句法信息的特征表现在6-9层,句⼦语义信息的特征表现在10-12层。
·主谓一致的特征表现在8-9层 (属于句法信息的一种)。
猜你喜欢:




















.jpg)