
全国中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2018-07-25 来源:黑马程序员 浏览量:
一、MySQL 与其他数据库的简单比较
1.1性能比较
性能方面,一直是MySQL 引以为自豪的一个特点。在权威的第三方评测机构多次测试较量各种数据库TPCC 值的过程中,MySQL 一直都有非常优异的表现,而且在其他所有商用的通用数据库管理系统中,仅仅只有Oracle 数据库能够与其一较高下。至于各种数据库详细的性能数据,我这里就不便记录,大家完全可以通过网上第三方评测机构公布的数据了解具体细节信息。
MySQL 一直以来奉行一个原则,那就是在保证足够的稳定性的前提下,尽可能的提高自身的处理能力。也就是说,在性能和功能方面,MySQL 第一考虑的要素主要还是性能,MySQL希望自己是一个在满足客户99%的功能需求的前提下,花掉剩下的大部分精力来性能努力,而不是希望自己是成为一个比其他任何数据库的功能都要强大的数据库产品。
1.2可靠性
关于可靠性的比较,并没有太多详细的评测比较数据,但是从目前业界的交流中可以了解到,几大商业厂商的数据库的可靠性肯定是没有太多值得怀疑的。但是做为开源数据库管理系统的代表,MySQL 也有非常优异的表现,而并不是像有些人心中所怀疑的那样,因为不是商业厂商所提供,就会不够稳定不够健壮。从当前最火的Facebook 这样大型的网站都是使用MySQL 数据库,就可以看出,MySQL 在稳定可靠性方面,并不会比我们的商业厂商的产品有太多逊色。而且排在全球前10 位的大型网站里面,大部分都有部分业务是运行在MySQL数据库环境上,如Yahoo,Google 等。
总的来说,MySQL 数据库在发展过程中一直有自己的三个原则:简单、高效、可靠。从上面的简单比较中,我们也可以看出,在MySQL 自己的所有三个原则上面,没有哪一项是做得不好的。而且,虽然功能并不是MySQL 自身所追求的三个原则之一,但是考虑到当前用户量的急剧增长,用户需求越来越越多样化,MySQL 也不得不在功能方面做出大量的努力,来不断满足客户的新需求。比如最近版本中出现的Eent Scheduler(类似于Oracle 的Job 功能),Partition 功能,自主研发的Maria 存储引擎在功能方面的扩展,Falcon 存储引擎对事务的支持等等,都证明了MySQL 在功能方面也开始了不懈的努力。
任何一种产品,都不可能是完美的,也不可能适用于所有用户。我们只有衡量了每一种产品的各种特性之后,从中选择出一种最适合于自身的产品。
二、MySQL 的主要适用场景
据说目前MySQL 用户已经达千万级别了,其中不乏企业级用户。可以说是目前最为流行的开源数据库管理系统软件了。任何产品都不可能是万能的,也不可能适用于所有的应用场景。
那么MySQL 到底在什么场景下适用什么场景下不适用呢?
1、Web 网站系统
Web 站点,是MySQL 最大的客户群,也是MySQL 发展史上最为重要的支撑力量,这一点在最开始的MySQL Server 简介部分就已经说明过。
MySQL 之所以能成为Web 站点开发者们最青睐的数据库管理系统,是因为MySQL 数据库的安装配置都非常简单,使用过程中的维护也不像很多大型商业数据库管理系统那么复杂,而且性能出色。还有一个非常重要的原因就是MySQL 是开放源代码的,完全可以免费使用。
2、日志记录系统
MySQL 数据库的插入和查询性能都非常的高效,如果设计地较好,在使用MyISAM 存储引擎的时候,两者可以做到互不锁定,达到很高的并发性能。所以,对需要大量的插入和查询日志记录的系统来说,MySQL 是非常不错的选择。比如处理用户的登录日志,操作日志等,都是非常适合的应用场景。
3、数据仓库系统
随着现在数据仓库数据量的飞速增长,我们需要的存储空间越来越大。数据量的不断增长,使数据的统计分析变得越来越低效,也越来越困难。怎么办?这里有几个主要的解决思路,一个是采用昂贵的高性能主机以提高计算性能,用高端存储设备提高I/O 性能,效果理想,但是成本非常高;第二个就是通过将数据复制到多台使用大容量硬盘的廉价pc server上,以提高整体计算性能和I/O 能力,效果尚可,存储空间有一定限制,成本低廉;第三个,通过将数据水平拆分,使用多台廉价的pc server 和本地磁盘来存放数据,每台机器上面都只有所有数据的一部分,解决了数据量的问题,所有pc server 一起并行计算,也解决了计算能力问题,通过中间代理程序调配各台机器的运算任务,既可以解决计算性能问题又可以解决I/O 性能问题,成本也很低廉。在上面的三个方案中,第二和第三个的实现,MySQL 都有较大的优势。通过MySQL 的简单复制功能,可以很好的将数据从一台主机复制到另外一台,不仅仅在局域网内可以复制,在广域网同样可以。当然,很多人可能会说,其他的数据库同样也可以做到,不是只有MySQL 有这样的功能。确实,很多数据库同样能做到,但是MySQL是免费的,其他数据库大多都是按照主机数量或者cpu 数量来收费,当我们使用大量的pcserver 的时候,license 费用相当惊人。第一个方案,基本上所有数据库系统都能够实现,但是其高昂的成本并不是每一个公司都能够承担的。
4、嵌入式系统
嵌入式环境对软件系统最大的限制是硬件资源非常有限,在嵌入式环境下运行的软件系统,必须是轻量级低消耗的软件。MySQL 在资源的使用方面的伸缩性非常大,可以在资源非常充裕的环境下运行,也可以在资源非常少的环境下正常运行。它对于嵌入式环境来说,是一种非常合适的数据库系统,而且MySQL 有专门针对于嵌入式环境的版本。
三、Query 语句对系统性能的影响
我想对于各位来说,肯定都清楚SQL 语句的优劣是对性能有影响的,但是到底有多大影响可能每个人都会有不同的体会,每个SQL 语句在优化之前和优化之后的性能差异也是各不相同,所以对于性能差异到底有多大这个问题我们我们这里就不做详细分析了。我们重点分析实现同样功能的不同SQL 语句在性能方面会产生较大的差异的根本原因,并通过一个较为典型的示例来对我们的分析做出相应的验证。
为什么返回完全相同结果集的不同SQL 语句,在执行性能方面存在差异呢?这里我们先从SQL 语句在数据库中执行并获取所需数据这个过程来做一个大概的分析了。
当MySQL Server 的连接线程接收到Client 端发送过来的SQL 请求之后,会经过一系列的分解Parse,进行相应的分析。然后,MySQL 会通过查询优化器模块(Optimizer)根据该SQL 所设涉及到的数据表的相关统计信息进行计算分析,然后再得出一个MySQL 认为最合理最优化的数据访问方式,也就是我们常说的“执行计划”,然后再根据所得到的执行计划通过调用存储引擎借口来获取相应数据。然后再将存储引擎返回的数据进行相关处理,并以Client 端所要求的格式作为结果集返回给Client 端的应用程序。
注:这里所说的统计数据,是我们通过ANALYZE TABLE 命令通知MySQL 对表的相关数据做分析之后所获得到的一些数据统计量。这些统计数据对MySQL 优化器而言是非常重要的,优化器所生成的执行计划的好坏,主要就是由这些统计数据所决定的。实际上,在其他一些数据库管理软件中也有类似相应的统计数据。
我们都知道,在数据库管理软件中,最大的性能瓶颈就是在于磁盘IO,也就是数据的存取操作上面。而对于同一份数据,当我们以不同方式去寻找其中的某一点内容的时候,所需要读取的数据量可能会有天壤之别,所消耗的资源也自然是区别甚大。所以,当我们需要从数据库中查询某个数据的时候,所消耗资源的多少主要就取决于数据库以一个什么样的数据读取方式来完成我们的查询请求,也就是取决于SQL 语句的执行计划。
对于唯一一个SQL 语句来说,经过MySQL Parse 之后分解的结构都是固定的,只要统计信息稳定,其执行计划基本上都是比较固定的。而不同写法的SQL 语句,经过MySQL Parse 之后分解的结构结构就可能完全不同,即使优化器使用完全一样的统计信息来进行优化,最后所得出的执行计划也可能完全不一样。而执行计划又是决定一个SQL 语句最终的资源消耗量的主要因素。所以,实现功能完全一样的SQL 语句,在性能上面可能会有差别巨大的性能消耗。当然,如果功能一样,而且经过MySQL 的优化器优化之后的执行计划也完全一致的不同SQL 语句在资源消耗方面可能就相差很小了。当然这里所指的消耗主要是IO 资源的消耗,并不包括CPU 的消耗。
下面我们将通过一两个具体的示例来分析写法不一样而功能完全相同的两条SQL 的在性能方面的差异。
示例一
需求:取出某个group(假设id 为100)下的用户编号(id),用户昵称(nick_name)、用户性别( sexuality ) 、用户签名( sign ) 和用户生日( birthday ) , 并按照加入组的时间(user_group.gmt_create)来进行倒序排列,取出前20 个。
解决方案一、
解决方案二、
我们先来看看执行计划: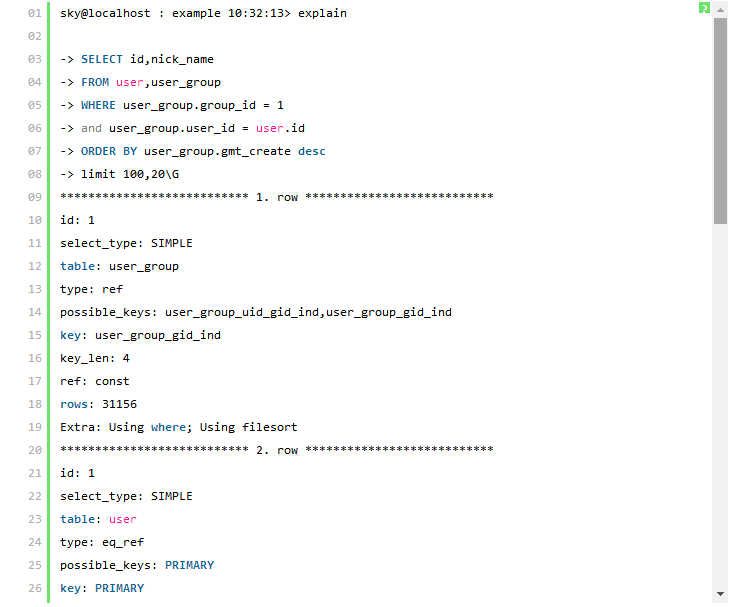
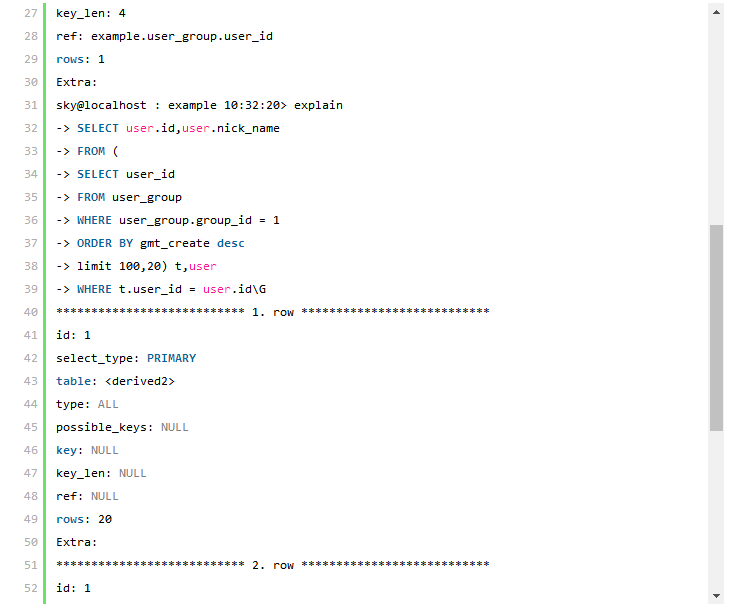
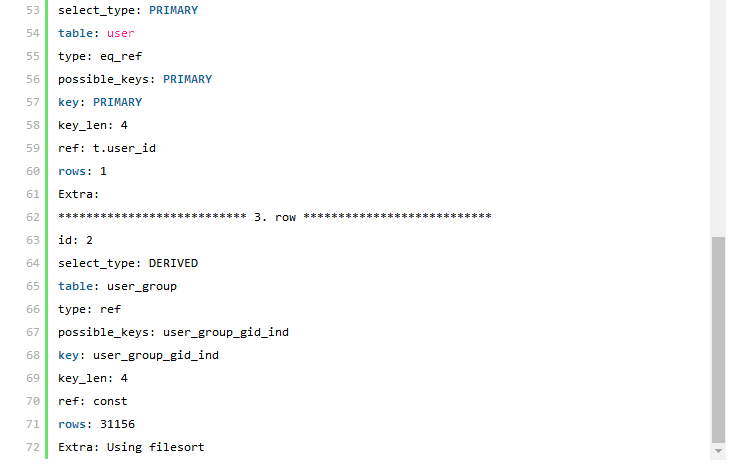
执行计划对比分析:
解决方案一中的执行计划显示MySQL 在对两个参与Join 的表都利用到了索引,user_group 表利用了user_group_gid_ind 索引( key: user_group_gid_ind ) , user 表利用到了主键索引( key:PRIMARY),在参与Join 前MySQL 通过Where 过滤后的结果集与user 表进行Join,最后通过排序取出Join 后结果的“limit 100,20”条结果返回。
解决方案二的SQL 语句利用到了子查询,所以执行计划会稍微复杂一些,首先可以看到两个表都和解决方案1 一样都利用到了索引(所使用的索引也完全一样),执行计划显示该子查询以user_group 为驱动,也就是先通过user_group 进行过滤并马上进行这一论的结果集排序,也就取得了SQL 中的“limit 100,20”条结果,然后与user 表进行Join,得到相应的数据。这里可能有人会怀疑在自查询中从user_group表所取得与user 表参与Join的记录条数并不是20 条,而是整个group_id=1 的所有结果。那么清大家看看该执行计划中的第一行,该行内容就充分说明了在外层查询中的所有的20 条记录全部被返回。 通过比较两个解决方案的执行计划,我们可以看到第一中解决方案中需要和user 表参与Join 的记录数MySQL 通过统计数据估算出来是31156,也就是通过user_group 表返回的所有满足group_id=1 的记录数(系统中的实际数据是20000)。而第二种解决方案的执行计划中,user 表参与Join 的数据就只有20条,两者相差很大,通过本节最初的分析,我们认为第二中解决方案应该明显优于第一种解决方案。
下面我们通过对比两个解决觉方案的SQL 实际执行的profile 详细信息,来验证我们上面的判断。由于SQL 语句执行所消耗的最大两部分资源就是IO和CPU,所以这里为了节约篇幅,仅列出BLOCK IO 和CPU两项profile 信息:先打开profiling 功能,然后分别执行两个解决方案的SQL 语句:

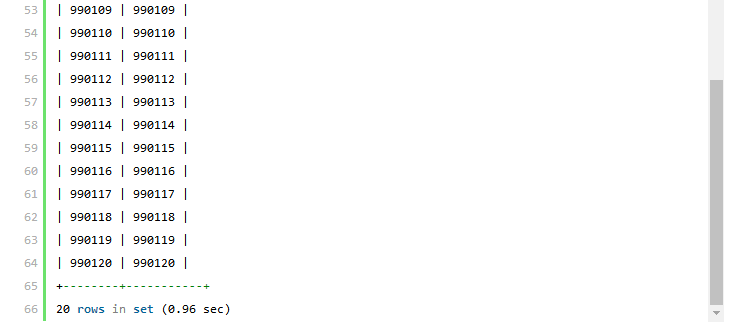
查看系统中的profile 信息,刚刚执行的两个SQL 语句的执行profile 信息已经记录下来了:

 我们先看看两条SQL 执行中的IO 消耗,两者区别就在于“Sorting result”,我们回顾一下前面执行计划的对比,两个解决方案的排序过滤数据的时机不一样,排序后需要取得的数据量一个是20000,一个是20,正好和这里的profile 信息吻合,第一种解决方案的“Sorting result”的IO 值是第二种解决方案的将近500 倍。然后再来看看CPU 消耗,所有消耗中,消耗最大的也是“Sorting result”这一项,第一个消耗多出的缘由和上面IO 消耗差异是一样的。结论:通过上面两条功能完全相同的SQL 语句的执行计划分析,以及通过实际执行后的profile 数据的验证,都证明了第二种解决方案优于第一种解决方案。同时通过后者的实际验证,也再次证明了我们前面所做的执行计划基本决定了SQL 语句性能。
我们先看看两条SQL 执行中的IO 消耗,两者区别就在于“Sorting result”,我们回顾一下前面执行计划的对比,两个解决方案的排序过滤数据的时机不一样,排序后需要取得的数据量一个是20000,一个是20,正好和这里的profile 信息吻合,第一种解决方案的“Sorting result”的IO 值是第二种解决方案的将近500 倍。然后再来看看CPU 消耗,所有消耗中,消耗最大的也是“Sorting result”这一项,第一个消耗多出的缘由和上面IO 消耗差异是一样的。结论:通过上面两条功能完全相同的SQL 语句的执行计划分析,以及通过实际执行后的profile 数据的验证,都证明了第二种解决方案优于第一种解决方案。同时通过后者的实际验证,也再次证明了我们前面所做的执行计划基本决定了SQL 语句性能。
首发:黑马程序员javaEE培训学院
首发:http://java.itheima.com/




















.jpg)